IPFS Architecture
Architecture
This lesson provides a digestible, top-level description of the IPFS protocol stack, the subsystems, and how they fit together. It delegates non-interface details to other sources as much as possible.
IPFS isn’t just one piece of software. It is a modular set of libraries and specifications that are designed to be used in various contexts. Not all implementations of IPFS will have the same diagram flow charts. Implementations are created for different use cases, so the different components they use will also vary.
Subsystems diagram
WIP: This is a high-level architecture diagram of the various sub-systems of Kubo (go-ipfs). To be updated with how they interact. Checkout the IPFS White Paper to gain a general & technical understanding of what IPFS is.
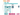
Introduction to IPFS Subsystems
When a file gets added to IPFS, it goes through many stages. Before a file can be shared with other peers, the following steps occur:
- The file is broken down into smaller block sizes
- Links are created to tie all the blocks together
- The blocks themselves have are written to storage You can learn more about this process in our earlier lesson: Introduction to IPFS.
The oldest implementation of IPFS is Kubo (formerly go-ipfs). In this lesson, we study processes primarily related to Kubo.
CoreAPI
The CoreAPI is how we interact with IPFS. It contains methods for common actions, such as adding and getting files. Additionally, it contains methods to interact with the datastore, merkle DAGs, keystore, remote pinning services, and many other components. With respect to Kubo, you can read more in the Kubo Command Line API docs page.
UnixFS
UnixFS is a data format for creating directory & file hierarchies. UnixFS is also responsible for breaking down a file into smaller pieces of data through a process called chunking. Then, UnixFS will add metadata to link those chunks together. This allows users to navigate the hierarchy that gets created like a file system on an everyday computer. The navigation tooling is called Mutable File System(MFS). Finally, every chunk in the hierarchy gets assigned a unique content identifier (CID), thus creating a Merkle DAG.

Linked Data
At the heart of IPFS is the Merkle DAG, a directed acyclic graph whose links are hashes. Hashes are the unique identifiers IPFS assigns to every piece of data through a process called hashing. This is what allows IPFS objects to be served by untrusted agents, data to be cached permanently, and any data structure to be represented as a Merkle DAG.
The InterPlanetary Linked Data (IPLD) project does not concern itself with files or directories; rather, the blocks themselves that get created out of these files. As part of the Dag Service component of Kubo, it can interpret and navigate the resulting Merkle DAGs for any kind of content addressed system. With any file type that’s added to IPFS, IPLD will be able to grab every subsequent chunk of data to return the final product.

Storage Mechanisms
Every implementation of IPFS will have different constraints or needs. But, they will always need a place to store the blocks of data that IPLD references. The Data Store service isn’t where data gets saved. Instead, is a generic API to allow app developers to swap out datastores seamlessly without changing application code.
With respect to Kubo, the Data Store is not only used for files that a user adds to the network, but also for the data that a user fetches from peers. It can be regulated manually or garbage collected. For information on how to do this with different implementations, please see their respective doc sites.
The default datastore in Kubo is called FlatFS. This Flat File System will make every block its own file and distribute them into various subdirectories, through a process called sharding. Some files added to IPFS may have hundreds or thousands of blocks, so having a manageable level of organization is important for faster reads and writes to disk.
ResNetLab: Content Routing
Peer & Content Routing
As discussed in the Content Addressing lesson, one benefit of content addressed data is that we can guarantee that the data we request is the data we will receive. Therefore, it does not matter who we receive data from. To enable this, IPFS uses a Distributed Hash Table (DHT) to find the addresses of peers who hold a specific piece of content. It is like the yellow pages of the distributed network world.
The DHT is a protocol from the libp2p toolbox that helps peers find any piece of data and who to grab that data from. Additionally, Kubo uses multiple libp2p libraries to open connections with peers and handle the transfer of data. But IPFS, as a file sharing protocol, does not need to use libp2p to find or transfer data. For example, an implementation can use IPFS Gateways accessed over http(s) to fetch data.
Bitswap is a message-based protocol that enables peers to exchange data. Bitswap is the default way Kubo enables a peer to request content from peers, then query connected peers (and the peers they are connected to), and facilitate the transfer for that information.
IPNS
IPNS is a self-certifying mutable pointer. Meaning any name that gets published is signed by a private key and anyone else can verify that it was signed by that peer with just the name. This self-certifying nature gives IPNS a number of super-powers not present in consensus systems (DNS, blockchain identifiers, etc.) like: mutable link information can come from anywhere, not just a particular service/system, and it is very fast and easy to confirm a link is authentic.
IPNS names are encapsulated by a data structure called an IPNS Record which contains the CID you are pointing to, the expiration date of a name and the sequence number which is incremented whenever the record is updated.
Issues with IPNS
- Resolving IPNS over DHT is slow - There may potentially be multiple versions of a record, so Kubo will spend up to a minute to try to find at least 16 peers to form a quorum.
- Safe Vs. Old problem - If a record expires, do I want my users to fetch and resolve the data anyways (serve old data) or not at all (safe). This is an ongoing and situational conversation.
- JS-IPFS in browsers - Users trying to use JS-IPNS in browsers run into a variety of issues. A workaround is using public gateways for resolving IPNS records and CIDs.
Check out the IPNS spec to gain a deeper understanding about IPNS records and how to use them.